
Creación de índices en PostgreSQL/PostGIS
La generación de índices dentro de las bases de datos debe ser un paso fundamental a la hora de modelar el diseño de la misma. Estos índices van a tener varias utilidades. Su principal beneficio será el de agilitar las consultas a los datos. Si bien en una tabla con pocas filas es casi inapreciable, cuando trabajo con millones de registros o tuplas el diseño de unos índices correctos es prioritario.

Photo by Nathan Dumlao on Unsplash
Si pensamos en el índice de un libro podremos tender un ejemplo claro de su utilidad. En un libro si queremos acceder a un capítulo concreto no iremos, o lo lógico es no ir, recorriendo hoja por hoja hasta localizar la página concreta del capítulo. La búsqueda pasará por ir al índice del libro, identificar el capítulo y acceder posteriormente a la página de inicio que se nos indica.
En una base de datos, el sistema es bastante parecido. El proyecto que ahora me encuentro titulado “Predicción inteligente de la variabilidad espacio-temporal de la aridez en el sur de España” dirigido por los profesores Javier Estévez y Amanda García del Departamento de Ingeniería Rural de la Universidad de Córdoba, la base de datos geográfica cuenta con una tabla de más de 16 millones de filas con mediciones diarias de variables de décadas de la red de estaciones meteorológicas de la AEMET (Agencia Estatal de Meteorología). Junto este conjunto de datos se encuentran también los datos para Andalucía de la Red de Alerta e Información Fitosanitaria (RAIF) y Red de Información Agroclimática de Andalucía (RIA).
En estas tablas es habitual la consulta de datos (temperatura, radiación, velocidad del tiempo, humedad…) de todas las estaciones para una fecha (día) concreto. Si no tenemos un índice sobre el campo ‘fecha’ y queremos obtener los datos del 26 de abril de 1976, el sistema irá accediendo de forma secuencial registro por registro buscando las coincidencias de la consulta hasta el final de la tabla. Sin embargo, si hemos creado un índice sobre el campo fecha para la tabla, la base de datos accederá primero al índice donde se indican los registros para esa fecha y posteriormente a las posiciones que le establece el índice sin tener que recorrer la tabla completa.
Por poner una cifras al asunto, la misma consulta a la tabla de los datos de AEMET sin filtro tardó en realizarse 43526 segundos devolviendo un resultado de 397 filas, mientras que con la tabla indexada el tiempo fue de 677 msec. Vemos claramente el ahorro de recursos y tiempo de procesamiento.
Viendo los resultados podríamos pensar que la generación de índices es una panacea y que hemos perdido gran parte de nuestra vida al no crear tantos índices como se nos ocurran con tal de “tunear” nuestra base de datos. Esto no es del todo cierto. Tenemos que tener en cuenta que los índices son estructuras de disco, por lo tanto archivos, lo que conlleva espacio y que también las actualizaciones de la tabla se demorarán ya que en estas también deben realizarse las actualizaciones de los índices que hayamos creado.
Creación de índices en PostgreSQL
Cuando cargamos una capa en la base de datos geográfica mediante QGIS esta nos permite crear de forma automática índices de tipo geográfico. Sin embargo, los índices sobre valores no espaciales hay que realizarlos mediante sentencias SQL. La firma para crear un índice de una única columna en PostgreSQL es la siguiente.
CREATE INDEX [nombre_del_indice]
ON [nombre_de_tabla] ([nombre_columna]);
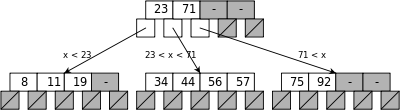
Existen varios tipos de índices: B-tree, Hash, GiST o GIN. Cada tipo de índice utiliza un algoritmo diferente que se adapta mejor a diferentes tipos de consultas. De forma predeterminada, el comando CREATE INDEX crea índices de B-tree (Árbol B), que se ajustan a las situaciones más comunes. Comentar también que al definir una Clave Primaria (PRIMARY KEY) sobre el campo de una tabla, este en sí se constituye como un índice, generando una restricción que impide que este campo se repita (UNIQUE) y que contenga valores nulos (NOT NULL).
Fuente: Wikipedia
Su pongamos que hemos cargado en nuestra base de datos PostgreSQL/PostGIS una capa poligonal con los de municipios de España (tbmunicipios). Si analizamos las consultas que pueden realizar se forma asidua sobre tabla, seguramente llegaremos a la conclusión que los campos con el nombre del municipio y el código único INE serán las columnas por la que más se van a realizar búsquedas. La tabla podría tener ya un índice si tiene definida como clave primaria el código INE. Sería interesante generar un índice (idx_municipios_nommunicipio) para la columna con el nombre del municipio (nom_municipio).
CREATE INDEX idx_tbmunicipios_nommunicipio
ON tbmunicipios (nom_municipio);
Índices para tablas geométricas (GiST)
Un índice espacial permite realizar de forma más eficaz determinadas operaciones en objetos espaciales (datos espaciales) en una columna del tipo de datos de geometry. El índice espacial reduce el número de objetos a los que es necesario aplicar las operaciones espaciales, que son relativamente costosas. A diferencia de las columnas no geográficas, para los índices espaciales se establece las cajas geográficas de las entidades. La caja (box) es el rectángulo definido por las máximas y mínimas coordenadas X e Y de una geometría.
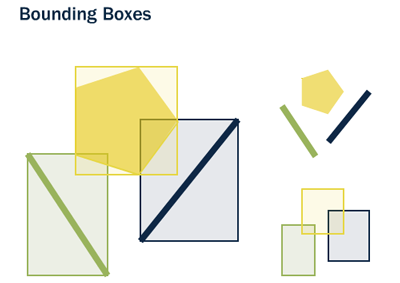
Fuente: Geotalleres
Los Sistemas de Información Geográfica como QGIS permiten generar este tipo de índices cuando añadimos datos a nuestra base de datos. En el caso que la tabla se haya creado desde cero, y que se trate de una tabla geográfica por supuesto, el código SQL sería parecido a al siguiente, adaptado a el ejemplo de la tabla de municipios.
CREATE INDEX idx_municipios_geom
ON municipios USING GIST (geom);
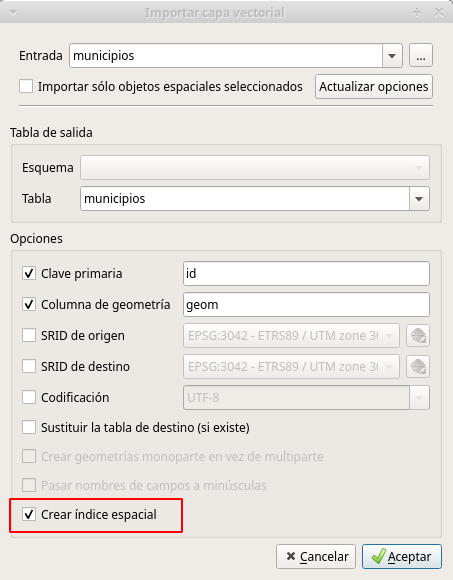
Opción de crear índice espacial en el Administrador de BBDD de QGIS

Comentar